
In the world of CRMs, data is king. It drives our understanding of customer behavior, informs our marketing strategies, and fuels our sales efforts. But what happens when that data is compromised by duplicates? This is a common issue faced by many businesses that have data flowing into their HubSpot CRM from a variety of sources.
Duplicate data can create a myriad of problems, including skewing reporting metrics, wasting valuable resources, and negatively impacting the customer experience.
But simply merging duplicates at random to rid yourself of their negative effects isn’t viable.
Let’s consider an example:
A customer, Jane Smith of Acme Inc., has three total records in HubSpot. The data that you actually want to keep may be split up between all three records. One might have Smith’s correct work email, another holds notes from sales and support conversations, and the third contains her most recent address, phone number, and job title from when she recently filled out a form. You want to keep all of the important information, but that kind of field-by-field level of control just isn’t possible using standard deduplication features.
In HubSpot, the merging process generally keeps the data from the record that has the most recently updated value. While this might seem like a logical approach, it's not always ideal. For example, if an older record contains more accurate information, this data would be lost in the merge, leading to potential inaccuracies in your CRM data that could impact the customer throughout their lifecycle.
Let’s delve into the intricacies of merging duplicates in HubSpot, focusing on the challenges of data retention. We'll explore how data retention when merging impacts your business, how HubSpot handles different fields during the merging process, the potential pitfalls to avoid, and best practices for maintaining the integrity of your data.

Merging Without Data Retention Control Has Risks
Duplicate data can have a significant negative impact on a company's operations, affecting everything from customer relationships to reporting accuracy. But deduplication alone won’t solve your problems if you do it without data retention control. Here are some of the consequences of such an approach:
- Inaccurate reporting: Duplicates alone can distort your data and lead to inaccurate reporting. Retaining the wrong data during a merge can skew reports, and you might not even realize it because you thought you were fixing a problem when you merged your duplicates.
- Wasted resources: Deduplicated records with poor data retention control can lead to wasted resources and time trying to engage with customers using errant data.
- Poor customer experience: While deduplicating records solves some customer experience problems surrounding duplicates, poor data retention can still yield less-than-ideal experiences for customers who can tell when your company is missing context or information in conversations and automated campaigns.
- Sales confusion: If you retain the wrong data after merging, your sales reps may be missing critical information. In account-based sales, retaining the wrong data in an important stakeholder record when merging could impact an entire account.
- Inefficient workflows: When reps are missing context for a record, they may look to other integrated apps and tools for additional context. Poor data retention causes employees to alter their workflow to search for necessary context they know is missing.
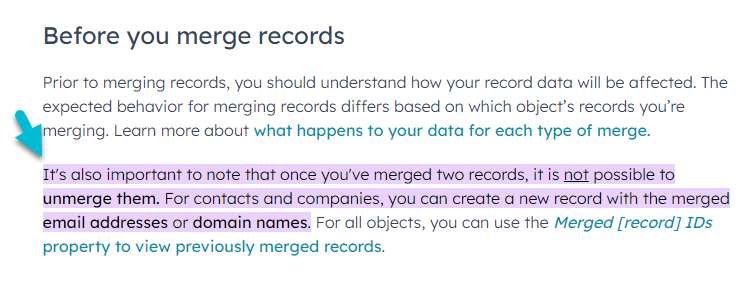
- Data loss: More generally, once data is merged in HubSpot, there is no way to undo the merge process to retrieve the lost data. It’s gone. So having poor data retention options is certain to lead to the loss of valuable data. Companies have to focus on minimizing that possibility.
Here is the relevant portion of the HubSpot help documentation that discusses this:
These issues are why it’s critical to retain the correct data during duplicate merging in HubSpot. It's not just about keeping your CRM tidy; it's about ensuring accurate reporting, efficient operations, and positive customer experiences.
How HubSpot Handles Data Retention When Merging
HubSpot’s merge functionality allows you to consolidate duplicate data, but doesn’t offer much data retention control.
HubSpot retains the property data from the record with the most recently updated value for most fields. It combines logged activities and associations from both original records, and also has specific rules for how it handles a few select fields. Here's a breakdown of these rules for some key fields:
- Company Name and Domain Name: When merging companies, the primary company's name and domain name are maintained, regardless of which was updated most recently.
- Email: When merging contacts, the primary contact's email address is maintained, and the secondary contact's email address is added as a secondary email.
- Lifecycle Stage: The lifecycle stage furthest down the funnel is maintained. For example, if one contact is a lead and the other is a customer, the merged contact will have a lifecycle stage of customer.
- Create Date: The value for the oldest record is maintained.
- Number of Unique Forms Submitted: Values from all merged records are combined. For example, if the primary contact has submitted three forms and the secondary contact has submitted two forms, the value for Number of Unique Forms Submitted will be five.
- Marketing Contact Status: If your account has marketing contacts, the most marketable status is kept. For example, if one contact is set as marketing and the other as non-marketing, the merged contact will be set as marketing.
- Analytics Properties: These properties are re-synced and you will see the total number of page views for both contacts combined.
- Email Information Properties: The primary contact's values will remain for these properties, including the opt-out properties.
Understanding these rules is crucial for ensuring the integrity of your data during the merging process. But checking into all of this requires a time-consuming manual process for each merge.
If a duplicate group has five duplicate records for one contact, are you going to compare all of the records side-by-side to see how the data will be retained? Will you edit the records to ensure that the right data is retained? Will you do this in HubSpot or Excel?
The truth is that because HubSpot works this way, most companies simply merge their records without any additional analysis of what data they would lose during the merge. They are more interested in ridding themselves of the issues the duplicate records cause, without thinking about the impact of the data they are losing in the process.
It's crucial to note that the action of merging two records in HubSpot is irreversible. This means that, if you realize a mistake after the merge, there's no "undo" button. You can't separate the merged record back into the original two records. This makes it extremely important to verify that the records you're merging are indeed duplicates.
Record Ownership
Record ownership retention is critical when merging. If a sales rep is currently working an account, you want to ensure they are retained as the owner after the merge. If you don't, a new owner may be retained, causing confusion with an owner trail can't be easily audited because HubSpot doesn't allow you to undo the merge.
However, when you are using HubSpot's automatic deduplication features, the most recently updated owner will be retained. While this may be the right choice sometimes, it won't be all of the time. And a small mistake like that could end up derailing a deal.
Then, if you have the record ownership settings set up to flow from the company record down to the associated contacts and deals, an errant owner assignment of the company would create errant owners for all associated records as well, creating a big mess that will need to be untangled.
HubSpot Data Retention Examples
Now let's look at a couple of examples showing how HubSpot would retain data in the master record based on its default settings.
Let's assume in this scenario that the duplicates were matched because they had identical phone numbers. Here is what might happen with other critical fields:
| ID | First Name | Last Name | Job Title | Products Bought (Multi-select picklist) | |
| 1 | Ted | Roosevelt | teddy.roosevelt@us.gov | POTUS* | Package A |
| 2 | Theodore | Roosevelt.* | t.roosevelt@us.gov | President | Package B* |
| 3* | Teddy* | R | teddyr1858@gmail.com* | Former President | Package C |
| Master Record | Teddy | Roosevelt. | teddyr1858@gmail.com | POTUS | Package B |
Fields marked with "*" are the most recently updated records for that field in the duplicate group.
There are a few issues here.
- ID: Because it was the most recently created record in the group, record #3 is chosen as the master record that all others will be merged into.
- First Name: Because 'Teddy' is the most recently updated value for this field, it is kept. This may or may not be the ideal first name to keep.
- Last Name: The last name with a period at the end is kept because it was the most recently updated in the duplicate group. Instead, you'd probably prefer to keep the version without the period from record #1.
- Email: Because the @gmail email address was the listed email on the chosen master record (the most recently created record), it is retained over the professional email address you prefer to keep.
- Job Title: POTUS is kept because it was most recently updated data in this field, but the proper title to retain would be "Former President."
- Products Bought: This field is a multiple checkbox field (also known as a multi-select picklist). In this example, you'd always want to retain all listed purchases in the master record. But because "Package B" was the most recently updated data point, it is the only value retained. In this example, you'd lose a lot of information about past purchases using HubSpot's baseline features.
If you had your choice, your ideal post-merge data retention would probably look more like this:
| ID | First Name | Last Name | Job Title | Products Bought | |
| 3 | Teddy | Roosevelt | t.roosevelt@us.gov | Former President | Package A, Package B, Package C |
In this example, HubSpot's deduplication settings would have resulted in a lot of lost data in the merge, along with less-than-ideal data retained in multiple fields. And this is just one contact. Consider how this would impact your organization across every merged contact and company in your HubSpot database.
The point here is that monitoring data retention when merging in HubSpot CRM is too difficult and time-consuming for most companies to bother with it. They simply use the standard deduplication features and hope for the best.
But those that go that route are underestimating the impact of not being able to customize their data retention settings. And those that do understand and place focus on data retention end up employing arduous manual processes to control it.
Advanced Data Retention Options in HubSpot Are Limited
HubSpot retains the property data from the record that has the most recently updated value for most fields. This presents a major challenge.
Retaining the most recently updated data might seem logical at first glance, as newer data is often assumed to be more accurate. However, this isn't always the case. Duplicate records could be created from many different sources, and there is no guarantee that the most recently created record has the most accurate or valuable information.
Consider a scenario where you have two contact records for the same person. The older record, "Contact A," has the correct phone number, but hasn’t been updated since it was created. However, the newer record, "Contact B," has an incorrect phone number that was mistakenly updated. If you were to merge these two records, HubSpot would keep the incorrect phone number from Contact B because it's the most recently updated value. The correct phone number from Contact A would be lost in the merge.
Now consider similar scenarios for every single field in your database. It’s easy to see how all records to be merged could have multiple data points that you would like to keep in the resulting post-merge master record.
Losing this data in the merge process can lead to confusion, inaccuracies in reporting, and potential loss of important customer information.
To get around these data retention limitations, HubSpot companies have adopted several strategies:
- Manual merging in HubSpot CRM: Some companies choose to manually merge records in HubSpot using the default features. This involves a meticulous review of each record's data before initiating the merge, ensuring that the most accurate data is in the record chosen as the primary, and potentially moving data around to ensure that the record with the most recently updated field contains the data that you want to keep. While this method can help maintain data accuracy, it's time-consuming and not feasible for businesses with large databases.
- Merging in Excel, then importing: Another strategy is to merge records manually in Excel and then import the merged records back into HubSpot and delete the old records. However, this method has its drawbacks. It can be a complex and error-prone process. Deleting old records can lead to the loss of historical data and disrupt the continuity of customer interactions. While you can bulk-merge in Excel, you’ll run into the same problem of not being left with the ideal data in the resulting master record after the merge unless you set up very complex rule-based functions to help you identify and retain the ideal data. To retain data, many end up manually moving data into the master record in the CSV, which is extremely time-consuming and not viable as a long-term solution.
- HubSpot apps: There are also third-party apps available that offer more advanced merging and data retention capabilities. These tools can provide more control over the merging process and help ensure you keep the data you need.
Understanding these potential solutions and their limitations can help you make an informed decision about how to handle duplicates and data retention in your HubSpot CRM. The choice of approach can be a balancing act between maintaining data accuracy, ease of use among your teams, managing resources, and ensuring a smooth and consistent customer experience.
Insycle: Your Data Retention Solution in HubSpot
Insycle is a robust customer data management solution that offers a comprehensive suite of features to address the challenges of data retention in CRM platforms like HubSpot. It provides a sophisticated approach to identifying and merging duplicate records, allowing businesses to maintain the correct data for every field in their HubSpot CRM database during the merging process.
Identify and Bulk-Merge Duplicate Records in Advanced Ways
Insycle's advanced duplicate detection capabilities allow you to use any field in your CRM as a criterion for identifying duplicates, offering a more thorough detection process than standard CRM features.
With Insycle, you can use any field in HubSpot as a duplicate matching field. You can opt for exact matching or similar (fuzzy) matching and even ignore certain aspects of matching records, such as numbers, symbols, and whitespace.
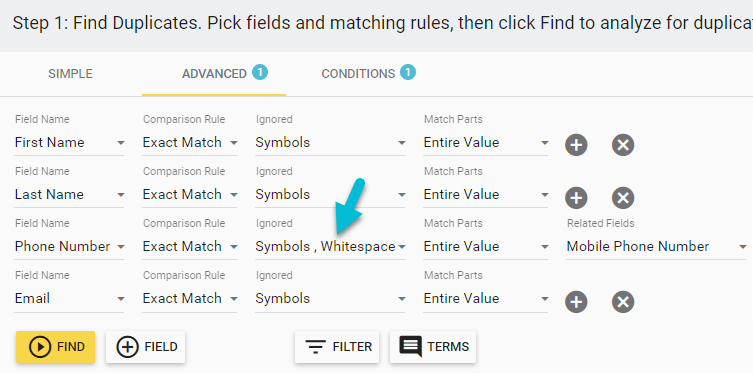
With Insycle’s deduplication flexibility, you’ll catch many more duplicates than you would through HubSpot’s standard duplicate identification features.
Additionally, Insycle allows you to compare your matching fields to related fields. For example, you might want to match duplicates by comparing the Phone Number field to the Mobile Phone Number field.
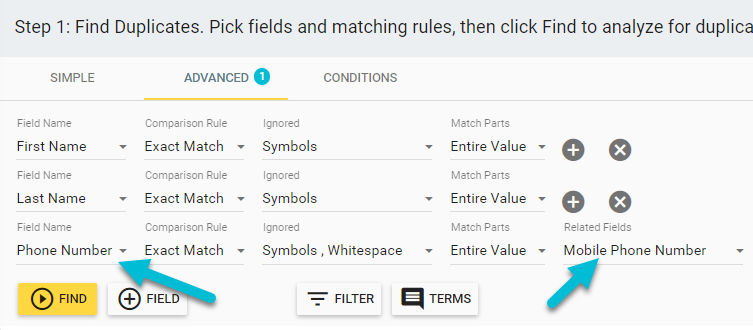
Rule-Based Master Record Selection
Insycle's rule-based master record selection feature provides granular control over the merging process. You can establish a set of rules to determine which record should be retained as the master after the merge. Insycle systematically applies these rules, eliminating records that don't meet the criteria until only the master record remains.
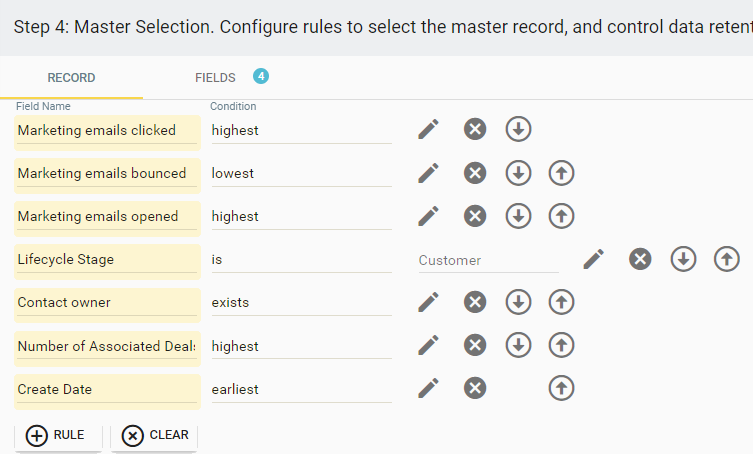
Rule-Based Data Retention Settings for Every Field
Then, you’ll have full control over your post-merge data retention with field-by-field rules. This means you can specify how each field's data should be handled during the merge. For example, you might instruct Insycle to retain the email from the master record, keep the contact owner from the record with the most recent sales activity, or consolidate all membership notes across the duplicate records in a custom field.
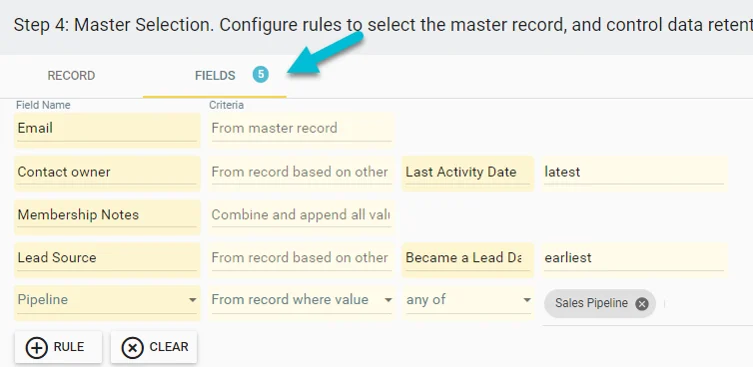
Additionally, Insycle can aggregate data from multiple records to preserve specific fields across all duplicates. For instance, if your duplicate contacts have multiple email addresses, you can direct Insycle to gather all these emails and compile them into an additional email field, ensuring no valuable data is lost in the merge.
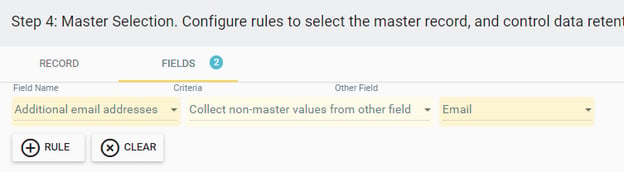
With Insycle, you have complete control over how your data is retained while merging in HubSpot.
Insycle Delivers Advanced Deduplication With Complete Data Retention Control
Insycle's approach to data retention provides businesses with a high level of control over their data during the merging process, making it a vital tool for maintaining database accuracy and efficiency. It allows you to establish data retention rules for every field, ensuring critical information is preserved during merges.
But Insycle is more than just a deduplication tool. It's a complete customer data management platform offering a suite of features to streamline and enhance your data management processes. Whether you're dealing with the complexities of merging duplicates, looking to optimize your data management workflows, or aiming to clean and organize your CRM, Insycle is equipped to help.
Explore how Insycle can empower you to fully harness the power of your HubSpot CRM data.









