
Do you have the same customer information stored in multiple places? If so, you have redundant data.
This sounds negative, but redundant data isn’t always a bad thing. Sometimes it’s necessary, such as when a company name is stored in both the contact record and the company record in your CRM. Such redundancy is necessary to ensure proper linking between records, personalized communications, and effective account-based marketing (ABM).
But some redundant data has a negative impact on your business. Duplicate data causes sales teams to step on each other’s toes and send mixed marketing messages. Redundant data can also make it challenging to know which records to access and update, slowing processes for anyone who uses them.
Bad redundancy causes embarrassing mistakes, creates confusion among your teams, and increases storage costs. Bad data costs U.S. businesses up to $3 trillion per year. And it’s no wonder—only 3% of companies meet basic data quality standards.
Good redundancy makes your organization more agile, efficient and protected against data loss and downtime.
Your strategy for dealing with redundant data depends on what kind of redundant data you have. Let’s examine the different types of redundant customer data.

Four Types of Redundant Customer Data
Redundant customer data falls into four categories, each with its own benefits or drawbacks:
- Redundancy across record types. The same data is stored across record types like contacts, companies, and deals. When implemented strategically, this type of redundancy can be useful.
- Redundancy on the same record type. Similar data stored in multiple fields and duplicate records are examples of redundant data on the same record type. This type of data redundancy, outside of specific use cases, is usually bad.
- Redundancy across systems/apps. This can be useful or problematic, depending on the application. Redundancy across systems is often unavoidable, and your primary systems will require reconciliation for consistency.
- Redundancy across infrastructure. Data redundancy across infrastructure is critical for reliable data backups that prevent data loss.
Data Redundancy Across Record Types
Redundant data across record types like contacts, owners, and deals is good when used strategically.
Sometimes, data redundancy is intentional—such as the example where “Company Name” is included on both contact and company records. Such redundancy makes it easier to find information, use data for automation, or create reports.
But even these useful applications of redundancy can come with downsides.
When you store the same data across record types, you have to have processes to ensure that the data syncs. Otherwise, this data will become inconsistent over time. That can confuse users, adding steps to their processes and increasing the likelihood of mistakenly using the wrong data.
When you want to fix data redundancy issues across record types, the process that you use is called “normalization.”
Normalizing Redundant Data Across Record Types
Normalization is a systematic approach to eliminating useless data redundancy across record types.
To put it more simply, normalizing CRM data ensures that all redundant data is necessary and consistently formatted and standardized across all of your record types. This requires defining standards for data fields, identifying and implementing solutions to enforce those standards, and doing so on an ongoing basis—manually or using automated solutions.
For example, if the “Company Name” on your contact record is “Microsoft” and the “Company Name” on your company record is “Microsoft Inc.” this is not normalized and consistent data. If this field were used in automation, mentions of the company using “Microsoft Inc.” would feel unnatural, making it obvious to the recipient that they are receiving automated communications. Such issues across the entirety of a database can lead to inaccurate information in communications, poor personalization, and confusion.
Data Redundancy on the Same Record Type
Redundant data on the same record type—such as contact records—is usually duplicate data.
Duplicate data is almost always problematic for customer data because it breaks what is known as the “single customer view.” This is a state where your team can be confident that your data is reliable. When you have a single customer view, employees know that all relevant captured data is stored on the customer record they find, and not split up between duplicate records.
When data for a single contact is stored on several records, it is more difficult to access that data. This impacts anyone who uses customer data. Marketing teams can’t be sure their personalization is accurate. Support teams don’t have all the information they need to help customers. Sales teams may not have the right context in prospect conversations. When you have high duplication rates, your customer reporting is skewed in unpredictable ways
To improve your data quality, you need to identify and merge duplicate records. This process is known as deduplication.
Deduplicating Redundant Data Across Record Types
Deduplication is the process of identifying and merging groups of duplicate records into a single master record that retains the most accurate and up-to-date data.
Strong deduplication processes mean that every person who uses a customer contact or company record does so with faith that they have access to all relevant information. This is a single customer view.
Maintaining a single customer view frees your teams from having to add steps to processes to check for additional context. It means they don’t have to conduct their own research before engaging with prospects and customers. It is also critical for account-based marketing. Having full context for all relevant stakeholders allows you to deliver a personalized experience to each one, addressing individual needs and concerns.
To deduplicate multiple redundant records of the same type, you must first identify a unique identifying field, also known as a matching field.
You can use this field to match duplicate records because it is unlikely that other, non-duplicate records will contain the same information. For instance, you might use fields like first and last name and additional fields like email, company domain, phone number, or mailing address to identify duplicate records in your database. There are many advanced methods for matching duplicates.
Then you determine how you would like to merge those records and what information to retain in the master record.
While some CRMs include deduplication features, identifying and merging all of your duplicates will often require a painstaking manual process in Excel. You’ll need to use advanced formulas to identify duplicate records and then merge them. This process involves a high probability of losing relevant data and harming employee morale.
Data Redundancy Across Systems/Apps
Every year, companies use more software to power their operations. Each app collects data. So each solution you add to your tech stack increases the amount of data that you collect.
As you add systems, redundant data is unavoidable. This can be a good thing or a bad thing. Redundant data across systems can make that data easier to access and easier to use. It can help you manage permissions by ensuring that departments only have access to data relevant to the systems they use.
However, redundant data across systems can increase storage costs. You also have to keep the data synced for consistency, which can be both time-consuming and expensive.
To ensure that your cross-system redundant data is consistent, you’ll need to compare the data stored in each of your critical systems. This process is known as reconciliation.
Reconciliation for Redundant Data Across Systems/Apps
It’s rare that companies do all of their work from one single system. Marketing, sales, and support all often use their own specific software to handle their job duties. Not having consistent data across these apps results in inconsistent experiences for the customer throughout their entire lifecycle with your company.
No one wants that. You can ensure your data is consistent, regardless of its location, through reconciliation. Reconciliation processes involve comparing one data source against another to look for inconsistencies and inaccuracies. When your data is reconciled, employees can work confidently from their primary app, without worrying that they are missing context that is stored on another app.
Without a simple way to compare, reconciliation involves manual checks. Alternatively, you can export data from both sources and compare them against one another using complicated Excel formulas.
Ultimately, if redundant data is not reconciled across your systems, you open yourself up to data quality issues wherever the outdated data is used.
Data Redundancy Across Infrastructure
Data redundancy across infrastructure is critical. This is especially true for large companies, where the stakes regarding infrastructure readiness and access are very high. A loss of valuable data or prolonged downtime could cost millions of dollars and impact a significant segment of customers.
Data redundancy across infrastructure increases access to data and makes businesses more resilient. When critical systems go down, you have backup access to data and can keep business flowing uninterrupted. And if someone cannot locate a subset of data, infrastructure data redundancy provides multiple avenues for finding it.
Storing redundant data across infrastructure also serves as a backup, mitigating potential data loss catastrophes. Should there be a warehouse fire or some other unexplained event, your data redundancy ensures that no data is lost.
How Insycle Helps Companies Deal With Redundant Data
There are a lot of processes involved in ensuring that your systems only contain beneficial redundant data. Insycle’s complete CRM data management platform helps companies manage all of them.
With Insycle, you can normalize, deduplicate, and reconcile redundant data to help you maximize the benefits and mitigate the downsides of data redundancy.
Normalizing Customer Data with Insycle
Normalizing redundant customer data is necessary across record types. There are many reasons to store the same data stored on two different record types. Still, you need that data to be consistent, or else you risk personalization errors and confusing situations for your team.
Insycle helps you to normalize data flexibly, in bulk. You can format and normalize fields like first and last names, company names, addresses, and phone numbers using Insycle’s pre-built templates.
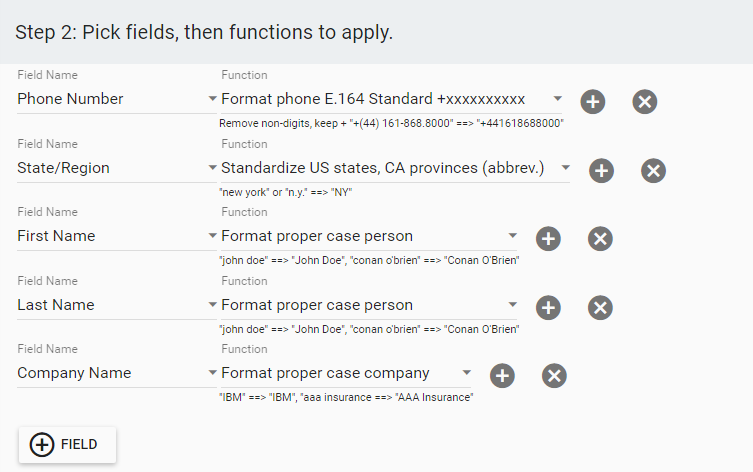
Normalizing and standardizing customer data with Insycle.
By applying these fixes to redundant data across multiple record types, you ensure that you are only storing consistently formatted and standardized data that you can use.
Deduplicating Customer Data with Insycle
Insycle offers advanced duplicate detection and smart merging for popular CRMs like HubSpot, Salesforce, Intercom, and Pipedrive.
Using Insycle’s pre-built templates, you can identify duplicates using a variety of field combinations, including:
- same name
- same name, same domain
- same name, similar company
- same last name and domain
- same name, same phone
- and many others, including your own custom properties
With Insycle, you can build custom templates using any field in your CRM as a matching field for duplicates. You can also harness advanced options for matching and parsing the data in those fields.
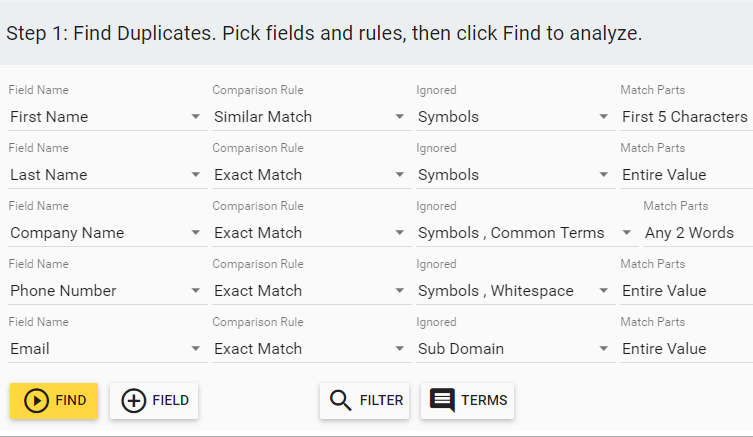
Identifying and merging duplicates in advanced ways using Insycle
Additionally, Insycle lets you determine what data to retain when merging records on a field-by-field basis, based on rules. Then, you can ensure that your final record includes the most up-to-date customer data from all records in the duplicate group.
Reconciling Data With Insycle
Insycle also allows you to compare and reconcile data between two different systems using CSVs.
You can export data from System A and compare it against the data contained in System B—your Insycle-connected system. Insycle compares data in your CSV to your CRM using your field matching settings, while also telling you which CSV records it was not able to match to CRM records, showing that they may be net new records.
Insycle shows you what the data will look like before and after importing your CSV data under your current template settings.
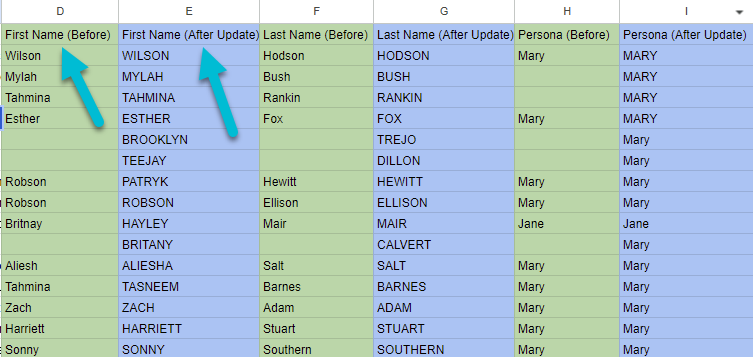
Comparing CSV Data to your CRM Data
This provides you with a simple but effective way to reconcile individual records or specific fields between two different systems.
Data Redundancy Is a Gift and a Curse
The four types of data redundancy include both good and bad redundancy. Good redundancy makes your organization more agile, efficient, and protected against data loss and downtime. Bad redundancies cause embarrassing mistakes, create confusion among your teams, and increase storage costs.
With Insycle, you can help remove the bad redundant data through deduplication while maximizing the benefits of positive redundant data with normalization, standardization, and reconciliation.
But Insycle isn’t just a tool for fixing redundant data issues. It’s a complete customer data management platform. Insycle enables operations teams to identify and fix CRM data quality issues in bulk while automating their most important data management processes. Without Insycle, the cost of bad data is often overlooked for companies, impacting their operations across their organization.
Is redundant data a net positive for your company or just a thorn in your side? Click here to learn more about how Insycle can help.









