
If you are responsible for managing customer data, it is almost certain that you have dealt with the headaches that duplicate data creates. Whether that duplicate data ended up in your system as the result of customers filling out forms, your team entering the data manually, or imports from outside platforms — the consequences of that duplicate data are the same, and quite costly.
In fact, the costs associated with duplicate data are higher than you’d imagine. Data quality problems cost U.S. businesses to the tune of more than $600 billion every year. Duplicate contacts, companies, and deals in your CRM may be the data problem most viscerally connected to those data-quality related costs. They harm customer relationships. They are common in most CRM databases and the impact on your marketing, sales, and support initiatives is often easily spotted.
Sales teams are critically impacted by duplicates. In databases with high duplicate rates, reps are forced to alter their standard sales processes to include checks for duplicates, or else they risk engaging prospects and accounts missing vital context, hurting customer relationships.
They harm your marketing automation by causing embarrassing mistakes that harm your brand reputation and drain your marketing budget. 40% of leads contain bad data. With 33% of companies having more than 100,000 customer records in their CRM, fixing those issues represents a substantial opportunity for growth.
Duplicate contact records also negatively impact your ability to offer a fulfilling customer service experience. If a customer connects with your support through phone, email, or live chat, your support will be slower and less effective when they have to dig through multiple customer records to find the right customer profile. Fast access to that customer data is critical to their job.
However, anyone who has done quite a bit of duplicate data cleaning knows that sticking to simple exact match values to identify duplicates is leaving a lot of meat on the bone. In fact, you might be leaving most of the duplicates in your database.
To truly master data deduplication in your CRM, you need to dig deeper.
When you begin to look beneath surface-level duplicates, you find that many in the average CRM database fall outside of the obvious exact-match duplicates, where the waters are more muddy.
These less conventional duplicate scenarios are much more common than most people think and are necessary to consider if you would like to remove duplicates from your database.
1. Non-standardized Names
One of the most common ways for duplicate customer data to go undetected in a database is through common terms being expressed in different ways.
Let’s consider some examples.
Let’s say that you were running a contact data deduplication process in HubSpot and are using a company name as one of the primary ways to match duplicate records within your database.
Well, the company name might be expressed differently in separate customer records that are actually duplicates.
For instance:
- Microsoft Inc.
- Microsoft Incorporated
Having the company name expressed in different ways is likely to cause you to miss duplicate records, even when the fact that they may be redundant data is obvious.
Let’s consider another example — job titles.
- CEO
- C.E.O.
- Chief Executive Officer
This is why data standardization is so critical. Otherwise, identifying duplicate customer data is nearly impossible. Ifyou don’t have standardization processes in place, your CRM is certain to have these kinds of duplicate records.
2. Short Names and Nicknames
People are often known by multiple names. They may use a shorter, more casual version of their first name, go by a nickname, or use initials.
For example, if a man’s name was Jonathan Paul Johnson, you might see his name represented in a number of different ways across multiple duplicate CRM contact records:
- Jonathan Johnson
- Jon Johnson
- Jon Paul Johnson
- Jonathan Paul Johnson
- J.P. Johnson
- JP Johnson
Beyond that, he might go by a nickname like “Bud,” “Junior,” or something unexpected. In any of these cases, it would be really easy to miss the duplicate record using normal duplicate detection procedures.
3. Typos
Typos are always present whenever humans are responsible for inputting data. So if you have customer or employee-facing forms (meaning that you don’t collect all data through automated means), you can be sure that you have duplicate data in your database that misses your checks due to those typos.
The average human data entry error rate is 1%. That means one out of every hundred keystrokes is likely to be wrong.
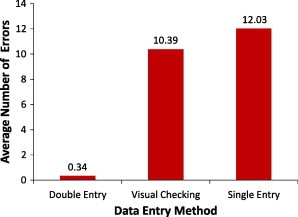
Source: Datapine
You might find issues with companies, like:
- Microsoft
- Microsift
Or with names, like:
- Jane
- Jame
Any field that uses human input data is going to have issues, especially in larger customer databases. These issues make it difficult to find duplicate customer data.
4. Titles & Suffixes
Contact data with a title of suffix can also cause you to miss otherwise obvious duplicate records in your customer database.
Using our previous example of a man names Jonathan Johnson, you might have duplicate records that look like:
- Dr. Jonathan Johnson
- Dr. Jon Johnson
- Mr. Jonathan Johnson
- Jonathan Johnson Jr.
- Jonathan Johnson III
- Jonathan Johnson Esq.
Title and suffix are considerations no matter where the data came from — whether it was entered by the person themselves or sourced from a third-party list.
5. Website URL Considerations
Using a website URL to find duplicate records is common for companies within a CRM.
Between two customer records, the field may or may not include the “www.” or the “http://” in the URL, causing you to miss duplicate records.
Or, different customer records may have different top-level domains. For instance, microsoft.com vs. microsoft.co.uk
Another common reason that duplicate records are missed is because of subdomains. For example, a university might have many departments leading to many different domain paths both as the listed URL or email domains — math.school.edu, english.school.edu, physics.school.edu, etc.
All of these website URL considerations need to be checked for to ensure that your database is clear of potential issues.
6. Matching by Similarity (AKA Fuzzy Matching)
Relying only on “exact match” identification is always certain to leave many duplicates floating around in your CRM. There are just too many variations that many fields might have for that to be effective.
“Fuzzy matching,” or approximate string matching, is a programmatic technique for analyzing data and identifying customer records that are similar, but not exact matches. It works by analyzing the “closeness” of two different data points.
Closeness is determined by measuring the number of changes necessary to make the two data points match. This is known as ‘edit distance,” which looks at the number of insertion, deletion, and substitution differences required to make two different points of data exact matches.
- insertion: bar → barn
- deletion: barn → bar
- substitution: barn → bark
Without similar and fuzzy-matching processes in place, you’ll never find all of the duplicates in a larger database.
In account-based marketing and sales, this can cause your team to miss out on engaging with critical stakeholders within the account and lead to missed sales.
Fuzzy matching duplicate customer data applies to almost any field in your CRM. There are all sorts of subtle differences that you’ll find in your database, most of which you would never think of until you saw it in action.
When you see just how common this problem is, you’ll naturally begin to wonder just how many of these issues are in your CRM and what kind of impact it is having on your bottom line.
7. External System IDs
External IDs are a necessity for integrating and syncing two disconnected platforms to correlate customer records across systems. Data deduplication processes often have to take these external system IDs into account to make sure that the contact data sync isn't broken.
As an example, maybe you want to use your marketing automation to send emails to your prospects and customers. Well, you want that to be reflected in your sales CRM too so that reps have a full context for their interactions.
Integrating HubSpot and Salesforce can cause many data problems between the two platforms.
The same is true for integrations between any two CRMs or different platforms that collect different types of data or use different field names to represent the same information.
In any popular CRM, one of the fields will be an ID number that is used to identify the record. This is a field that is perfect for identifying duplicate records that is often overlooked in data cleaning processes.
For instance, you could use the Salesforce Contact ID to identify duplicate contact records in HubSpot. Changes to your data in HubSpot might have forced the sync to create two different entries when it really should have appended or updated data in the original record.
8. “This or That” Duplicate Detection
One big issue is that many duplicate customer records slip through the cracks because the company is focused on identifying duplicates using set fields, without putting any secondary checks in place to ensure they don’t miss any.
For instance, you might primarily identify duplicates by first name, last name, and phone number. You catch most of your duplicate records by checking that combination of fields.
But inputting a secondary check when the first fails to identify a duplicate, such as First Name, Last Name, Address, can help you to find and fix free-floating duplicates that otherwise would have been missed.
9. Phone Numbers in Different Formats
Phone numbers are often used to identify duplicate contacts and duplicate accounts in CRMs.
It makes sense. A contact with two duplicate records would be likely to have entered the same phone number for both. Additionally, organizations are unlikely to change their mainline numbers often, so that can serve as a reliable field for duplicate detection.
However, there are some problems with using phone numbers as a primary field for this purpose.
First — there are many ways that a phone number can be formatted in your database. For example:
- 1234567890
- 123-456-7890
- (123)-456-7890
- 123.456.7890
- 1-123-456-7890
- 123 456 7890
- Etc.
This usually means that using the phone number field will leave a lot of unidentified duplicates in your database.
This field is one that is also likely to contain a lot of typos and other issues. That means that they might contain spaces or incorrect numbers. They might include an extension number, leading to the includes of the “#” in some of your phone fields.
10. Checking Across Similar Fields
Your CRM might collect data in fields that are similar to each other, causing a higher likelihood of misplaced or redundant data in your system.
For instance, you might collect several different types of phone numbers for a contact:
- Phone Number
- Mobile Number
- Company Phone Number
- Fax
Mistakes happen and you may find that a contact’s mobile number entered into a duplicate record’s company phone number field. Those kinds of duplicate records would be hard to spot unless you evaluated duplicate data across multiple similar fields.
11. Partial Matches
This is a duplicate data issue that would be very difficult to catch using Excel functions and VLOOKUP.
Let’s consider an example. Let’s say that you have a contact in your CRM from a large organization, like a University. Contacts in separate departments should be treated differently from one another because decisions are made independently in each department.
You could use partial matching to identify duplicates that share similarities with each other. For instance, you could use partial matching to detect a duplicate record for a prospect that had their employer listed in multiple different ways:
- University of Washington
- University of Washington School of Business
- Washington University School of Business
When you engage with this person, you want to make sure that you engage them with a full understanding of who they are and how to approach them. That might affect their lead score and prospect prioritization, provide critical context to sales teams, and determine the marketing campaigns that they would receive .
Insycle — Advanced Duplicate Detection
Insycle offers advanced duplicate detection and smart merging for popular CRMs like HubSpot, Salesforce, Intercom, and Pipedrive.
Using Insycle, you can use our pre-built templates to identify duplicates using a variety of field combinations including:
- Same name
- Same name, same domain
- Same name, similar company
- Same last name and domain
- Same name, same phone
- And many others, including your own custom properties
In fact, the Insycle Customer Data Health Assessment audits your data for common data errors when you sign up and automatically tracks multiple different types of duplicates.
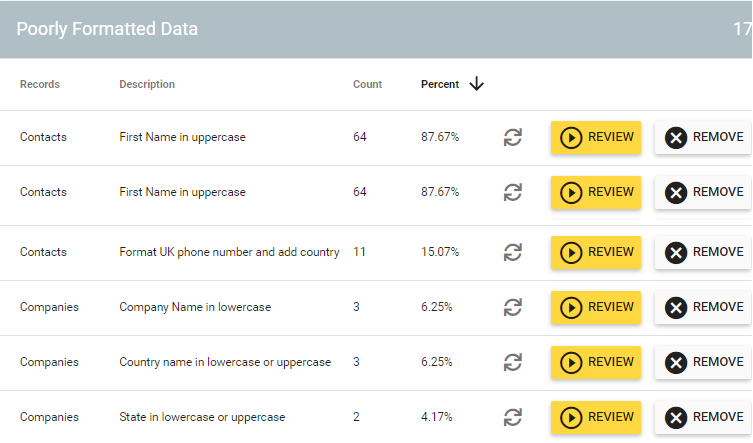
Insycle includes dozens of pre-built templates for identifying duplicate contacts, companies, and deals in popular CRM platforms.
Insycle also includes templates for “similar” or “fuzzy matching” — designed to help you catch more potentially duplicate records across your database. Many customer records are truly duplicates, but will never be identified with standard matching algorithms.
Most deduplication processes require that data be standardized before beginning. This makes it easier to identify potential duplicates using functions that are generally looking for exact-match duplicates.
However, Insycle is able to catch duplicates that would otherwise go missed. For example, when we discussed “common terms, expressed differently” we gave you the following example:
- Microsoft Inc.
- Microsoft Incorporated
These values represent the same company but would not be picked up by exact match deduplication processes.
Insycle is able to identify and match duplicates by ignoring common terms in the values. In this case, the common terms would be “Inc.” and “Incorporated”, and Insycle can match “Microsoft Inc.” and “Microsoft Incorporated” despite the inconsistencies in the company naming convention.
That feature isn’t limited to company names, either. It can do the same for phone numbers, where Insycle is able to compare the digits in the field while ignoring spaces, symbols, and formatting.
Standardizing your data is important. It’s critical for data management and improving customer experiences. But companies without perfect data standardization , can still use Insycle to dedupe even while the underlying data is messy or inconsistent.
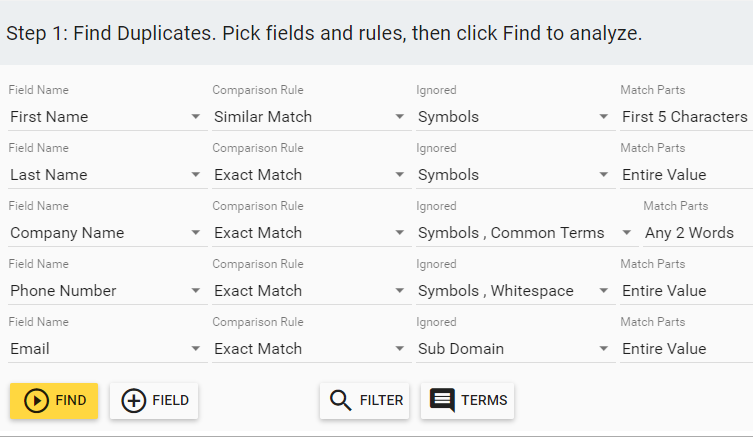
You aren’t just limited to the pre-built templates either. You can create your own templates for detecting duplicates in Insycle, using any combination of fields and exact vs. similar matching.
Dealing with duplicates is one step in the journey of managing your customer data and improving your results from your marketing and sales efforts.
Insycle is a complete customer data management solution for popular CRM systems. Using Insycle, you can cleanse, standardize, deduplicate, and automate customer recordsfuzzy updates to keep your data pristine.
So how about you? Do you have any unique duplicates you’ve encountered, or have any duplicate customer data horror stories to share?









